CTFのpwn問題の脆弱性を自動で見つけたかったけど微妙なのができた話
200日以上ぶりのブログ更新です。
残念ながら今年は仕事に私生活が忙しく、全くCTFを楽しむ余裕がありませんでした。
来年こそ、CTFにどっぷりつかりたいですね
さて、今回の本題です。
ご存じの通りpwn問には様々なバリエーションがあります。
等など…
これらのジャンルによる区分はあるものの、問題の解き方を抽象的にみると、
シェルコード問以外は概ね同じだと私は考えています。
具体的には①脆弱性発見し ②脆弱性を攻撃する というプロセスは共通ですね。
例えば、seccon4b 2023のNoControl(Linuxのユーザランドエクスプロイト)については私は下記の方法で解きました。
ec-pwn.hatenablog.com
①脆弱性を発見する ー> メモリ領域の初期化漏れとUSE AFTER FREE
②脆弱性を攻撃する ー> TCACHE POISONNINGとHOUSE OF SPIRIT
(この問題の私の解き方は冗長ではありますが、)
PWN問を解くときに、使えそうな脆弱性を見落とすことなく見つけることがファーストステップとしては非常に重要です。
問題によっては脆弱性が自明なことも多くあります。
特に比較的簡単なバッファオーバーフローの問題等は自明であることが多いです。
しかしながら、中級者向け以上の問題においては、バイナリが比較的複雑であったり、脆弱性が off by oneのようにあまり目立たないものであったり、
レースコンディションのように脆弱性があってもうまく使わないとクラッシュしないものであったり、脆弱性の発見自体が難しいこともあり、
私はCTFの問題を解く際に、かなり苦しい部分になっているのがこの脆弱性発見です。
脆弱性の発見を行うためにはどうすればいいのでしょうか。
この部分のノウハウは中々情報が少ないと感じていますが、一般的には下記の方法があると私は考えています。
1.静的解析
GHIDRAやIDAででコンパイルした結果、あるいは配布されたソースコードを眺めて脆弱性を見つける
2. 簡単な動的解析
とりあえずいろんな境界条件、大きな値や長いペイロード、書式文字列等を手作業で入れてみる
3.ファジング
ファジング用のプログラムを組む、あるいはAFL等でバイナリをファジングしてみる
私個人としては上記の手法によって脆弱性を見つける比率は
それぞれ10%、75%、15% の成功率くらいでしょうか。
私はIT業界にいるわけでもない、いわゆる趣味プログラマです。
ソースコードをちゃんと見る能力もあまりないので、静的解析もできません。
そうなると適当な値を入れて解けるか試す、といった簡単な動的解析に依存することが多くなってしまっていますが、
「なんかよくわからんけどクラッシュするというペイロードを見つける」といった行為に時間を費やしてて、
このプロセスが次第に運ゲーになってしまっており、回答率が安定しないという苦しさを味わっています。
(ちなみに運ゲーになりつつも、なんとなくノウハウというかジンクス的なものがある気がします。
例えば、メモ系のヒープの問題はEDIT機能に脆弱性があることが多い…等)
という中で、第4の方法として、CHAT GPTというかOPEN AIの何かに聞いてみようよというのが趣旨です。
うまくいくわけないよね、と思いながらとりあえずCHAT GPT 4に聞いてみます。
$20の働きはしてくれるのでしょうか?
題材は先ほどのNoControlです。
とりあえず「mallocの初期化漏れ」と、「Use After Free」を発見できるのでしょうか?

このC言語のコードには、セキュリティの観点からいくつかの潜在的な脆弱性が存在します。以下に主なものを指摘します:
1. **バッファオーバーフロー(`update_memo` 関数)**:
- `update_memo` 関数では、`read` システムコールを使用してユーザーからの入力を `memo` バッファに格納しています。
- しかし、`read` は `MEMO_SIZE` (0x80、128バイト) よりも多くのデータを受け取ると、バッファオーバーフローが発生します。
- これにより、隣接するメモリ領域が上書きされ、潜在的に任意のコード実行や他の危険な動作を引き起こす可能性があります。2. **ヌルポインタデリファレンス(`read_memo` と `update_memo` 関数)**:
- `read_memo` と `update_memo` は、`memo = memos[idx];` の後に `memo` がヌルかどうかをチェックしていますが、`puts(memo);` または `read(STDIN_FILENO, memo, MEMO_SIZE);` の実行前にヌルポインタチェックを行っていません。
- これはヌルポインタデリファレンスを引き起こし、プログラムがクラッシュする可能性があります。3. **整数オーバーフロー(`ask_index` 関数)**:
- `ask_index` 関数で、ユーザーからの入力を `atoi` 関数を使用して整数に変換しています。
- この入力が非常に大きい数値の場合、整数オーバーフローが発生し、結果的に不正なインデックスが生成される可能性があります。4. **フォーマット文字列の脆弱性**:
- コード全体を通じて `printf` 関数が安全に使用されていますが、ユーザーの入力をそのまま `printf` などのフォーマット関数に渡すと、フォーマット文字列の脆弱性が発生する可能性があります。5. **メモリリーク**:
- `delete_memo` 関数では、割り当てられたメモリを解放していますが、プログラムの他の部分でメモリ割り当てが失敗した場合の適切な処理が行われていません。
- これはメモリリークを引き起こす可能性があります。これらは一部の脆弱性であり、コードの全体的な構造とセキュリティ慣行によっては、他にも問題が存在する可能性があります。
ということでダメでした。
ものすごくそれっぽいのですが、まるっきりダメです。チャットGPTってソースコードは得意だった気がするのですが
生成ができるけど解釈はあまり得意じゃないんですかね。
ここでほかのアプローチを考えます。
それは、既存のpwn問題のバイナリと類似した問題を引っ張ってくれば、類似したところに脆弱性があるんじゃないのか。という発想です。
ひとことでいうと、OpenAIのEmbeddingの使って同じような過去問を見つけようということです。
既にPythonコードでOpenAI のEmbeddingを用いたコードの分析をやられている方がいらっしゃるようで、
結果を拝見する限りある程度は期待できそうです。
インフラ構成は適当に考えました。とりあえず下記の通りです。
フロントエンドはもはやアップローダーでしかないのでstremlitで5分くらいで作ります。
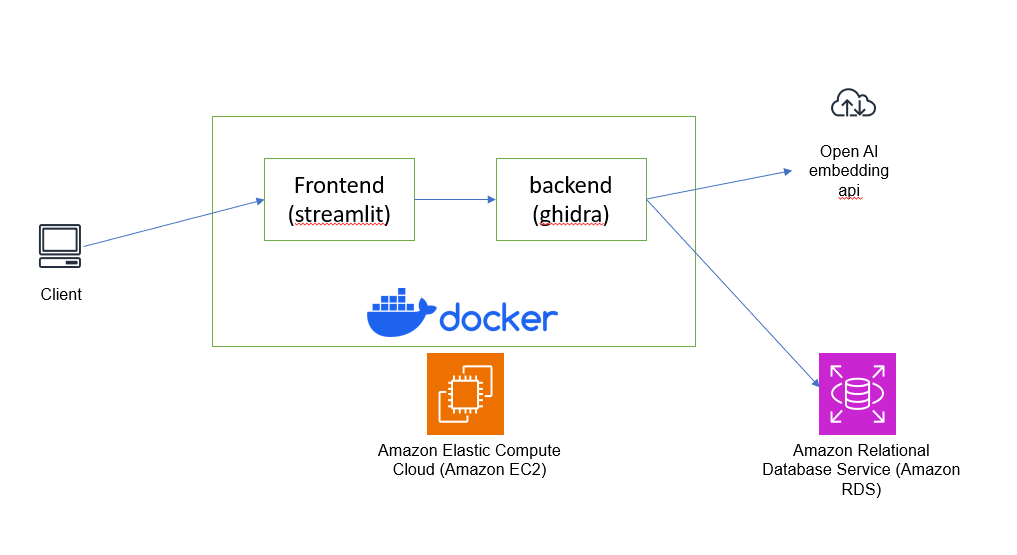
バックエンドは、ghidraが動いていて、アップロードされてきたバイナリをでコンパイルします。
デコンパイルした結果は、ある程度分割した後Open AIのEmbedding APIに投げることでベクトル化します。
ベクトル化された結果は、AWSのRDSのpostgresのpgvectorで保存されます。
シンプルすぎてこれ以上説明できないのですが
あえて言うなら多分RDSもEC2も分析用途にはいらなくて、
全部ローカルでDockerでやればいいです。なので、AWSを使う必要はないです。実際、EC2とか書いてますが
記事執筆時点では動かしてなくてローカルのDocker環境でやっています。EC2とかRDSとか書いた方がかっこいいと思って書いてます。
分析結果:過去問をTSNEで可視化
下記はとりあえず過去問を二次元上に可視化してみたものです。2次元への射影にはTSNEを利用しています。
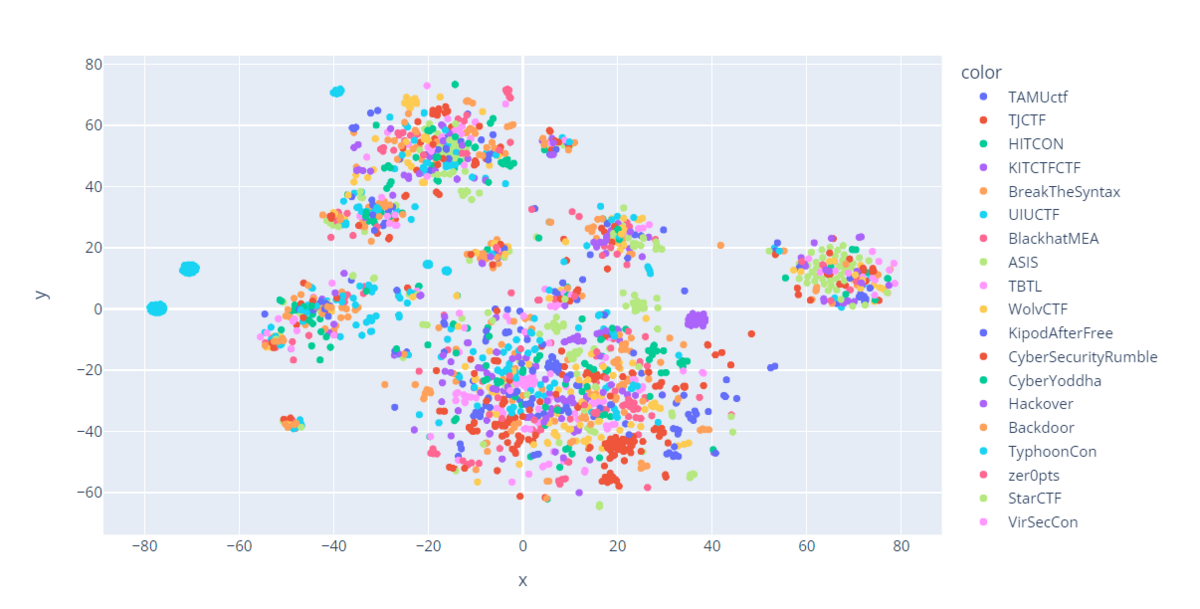
さて、見ての通り、どちらかといえば問題の傾向より、「CTFの大会名」例えばSECCONはSECCON等で分かれていることがわかりますね。
これはおそらく、問題の傾向で分類ができているわけではなく、同じ作者が利用している開発環境などに引っ張られてしまっているということだと思われます。
とはいえ、実は同じ大会でも点が散らばったりしていて、見た感じだとよくわかりませんね。
もう少しだけ、見たことある問題で見てみましょう。
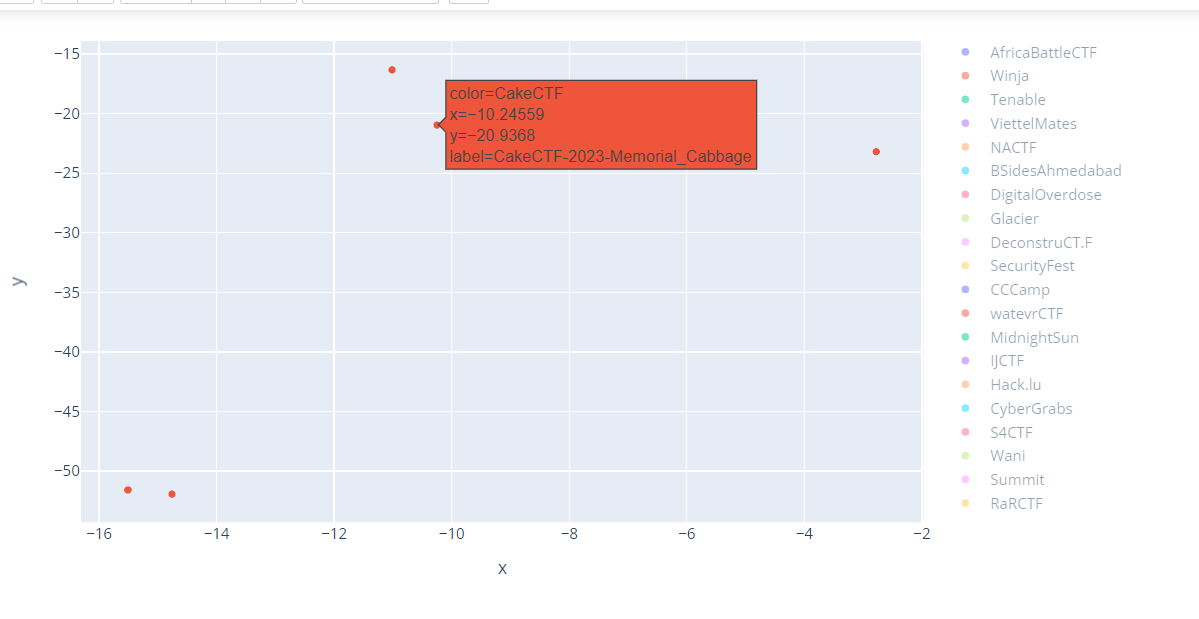
これはcalectfだけを抽出したものです。
この2023年に出題されたMemorial Cabbageに近い位置にいるのは、2022年に出題されたcrc2sumです。
Memorial Cabbage:ファイル操作の際の文字列を加工して権限昇格
crc2sum:ファイル操作のレースコンディションでHEAP BOFを利用して権限昇格
ということで、脆弱性という意味では違うもののようでした。
ファイル操作系PWNとでもいうのでしょうか。類題ではあるのですが…
分析結果:CakeCTF ctrc2sumの類似問題を引っ張ってみる
これは私が5分で作ったアップロード画面。
ここに問題をアップロードすると、いくつかを出してくれます。
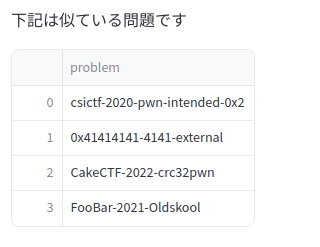
まずcsictfの問題は、全く関係ないbofの問題でした。
foobar ctfの問題も、bofの問題であまり関係ありませんでした。
ここから、すでにあまり精度が高くないことがうかがいしれます。
分析結果:Seccon4b No Controlの類似問題を引っ張ってみる
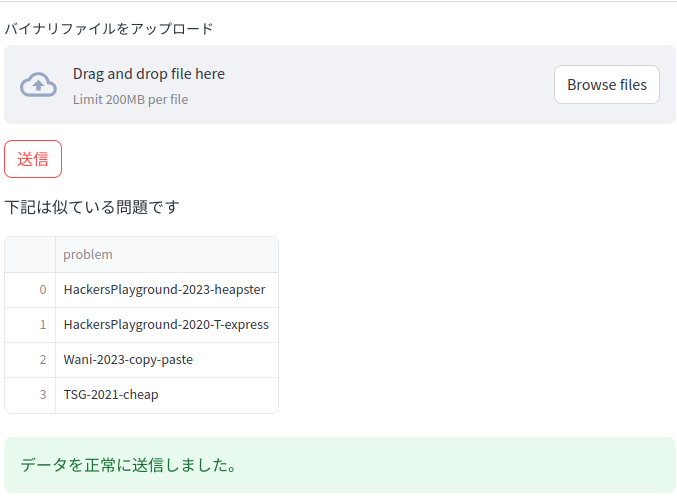
これが結果でした。
さて、出てきた結果を吟味してみましょう。
Wani(2023) copy-paste: heap bof
TSG(2021) cheap: heap bof
ということで、まぁheap問題だけど、脆弱性という観点では違うよね。ということになりました。
結論
- とりあえずGhidraでdecompileした後にOpenAI Embeddingに突っ込んで分類すると、問題自体の傾向よりも、開発環境や作成者起因の分類、あるいは問題で使われている関数の傾向による分類になってしまうようだ。
この問題はこの作者が作っているから作者のブログを読む、というメタ読みも無くはないが、そんなものはこのロジックを使わなくてもいけるはず。
ひとまず、とりあえず突っ込んだだけでは脆弱性が同じという粒度では探すことができなかった。というか、オリジナリティあふれる問題が数多くある中で、そもそも脆弱性が同じ問題ってそんなあるのかなっていう気もする。
かかったお金
OpenAIのお金 手持ちの問題をベクトルかするのに$12
AWSのお金 月額大体$20くらい。結局Dockerでローカルに立てたのでEC2は使わず。RDS代だけ。
合計、大体 月額$32 😡
今後の課題
・アルゴリズム回りの改善点
- openAIのEmbeddingはあまり精度が出なかったので、もっとソースコードに特化した埋め込みベクトルを利用してみようと思う。
- あとは、教師あり学習は避けて通れない気がする。人間がアノテーションして、この部分に脆弱性があるとか教え込むとか。面倒だけど来年あたりやってみようかな。
・実装周りの話
- 類似度が数値として出るように書き換える(簡単そうだけどめんどい)